

Why Most AI Coding Rollouts Stall
Early wins with AI coding are easy to find. Turning them into a repeatable team practice is the hard part.

Last week I argued that the market is describing agentic development in more mature terms than most teams are actually experiencing it. This week, I want to stay closer to the ground: where do rollouts actually start to break down?
In my talks with other engineering teams, I keep hearing some version of the same story. A team starts using AI coding tools and gets a few quick wins. A feature ships faster than expected. Somebody untangles a part of the codebase they have been avoiding. Somebody knocks out a bug, some tests, or an integration task that had been sitting there too long.
At first, it feels like a breakthrough. Then the friction shows up. Review takes longer than people expected. The agent made changes, but it is not always obvious which ones matter, what assumptions it made, or whether the code is actually right versus just plausible. Context gets lost between sessions. The wins stay concentrated in the hands of the one person who really knows how to drive the thing. Leadership starts asking harder questions about whether the gains are real, and the people closest to the work start giving long answers instead of clean ones.
I have heard some version of that story enough times now that I do not think it is an edge case. I think it is where most rollouts stall.
And I do not think the main problem is model capability.
The issue is that early AI coding wins are easy to demo and hard to operationalize.
That gap matters. Because once a team gets past the novelty phase, the question changes. It stops being, “Can this tool write code?” and becomes, “Can this team reliably work this way without creating more drag somewhere else?”
That is a much harder question.
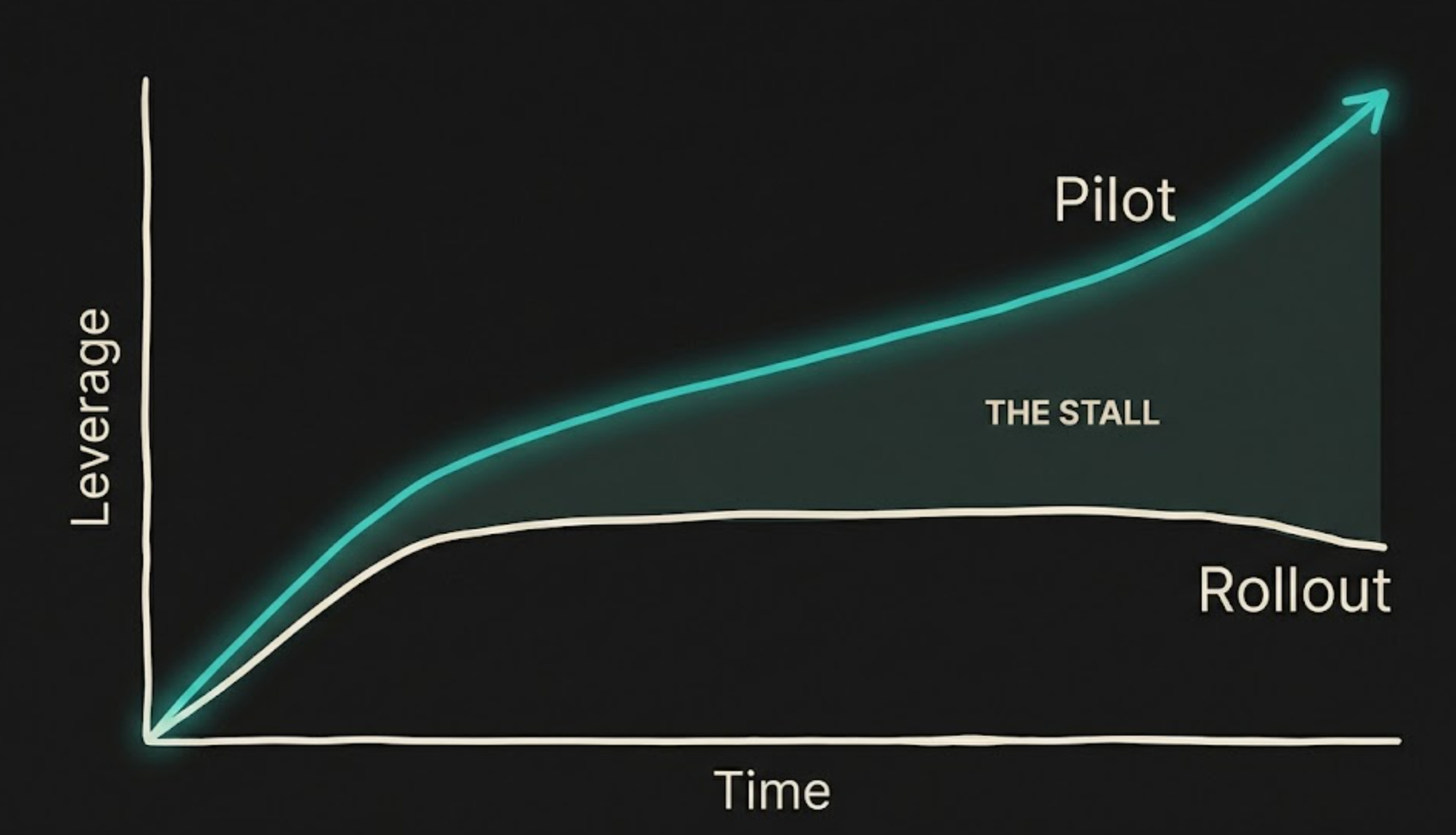
The pilot works. The rollout doesn’t.
One pattern I keep seeing in teams I have talked to is that the pilot goes better than the rollout.
That is not surprising. Pilots are narrow by design. They usually happen in the hands of the most motivated person on the team, on work that is relatively bounded, with a lot of extra attention around prompt quality, tool choice, and review. Under those conditions, AI coding can feel incredible.
Then the team tries to broaden usage.
Now more people are involved. The work is messier. The codebase is less familiar. The specs are less crisp. The standards are less consistent. The task is no longer “see if we can make this work” but “make this part of how we actually ship.”
That is where the friction shows up.
One solo founder I spoke with is shipping on Claude Code and Replit, while stitching context across Notion, Apple Notes, GitHub, and Google Docs. Parts of the workflow are genuinely fast. But the planning still takes hours. Testing still takes hours. When something goes sideways, the problem is not that the model failed to generate code. The problem is that the workflow has no real safety net. No escalation path. No shared operating rhythm. No clean way to know whether the result is solid or just plausible.
I have also talked with a team using three distinct agent roles for design shaping, orchestration, and deployment readiness through a custom harness one engineer largely maintains. That is real progress. But the workflow is still bespoke enough that it lives mostly inside the heads and habits of the people closest to it. Which means it works, but it does not yet scale socially inside the team.
And then there are teams in the middle, where the tool is present, the excitement is real, but the process around it never quite matures. The engineer uses AI one way. The product person documents things another way. Review still happens manually. Context lives in too many places. Ownership gets fuzzy. Nobody is fully sure what the standard operating model is supposed to be.
Those teams are not blocked because the models are dumb.
They are blocked because they have not turned isolated leverage into a repeatable system.
Most teams are trying to scale a moment, not a workflow
This is the part I think the market still talks around.
A lot of teams are not really scaling an AI workflow. They are trying to scale a moment.
The moment is real. It is the feeling of watching an agent do in ten minutes what used to take half a day. It is the experience of dropping into a messy codebase and getting oriented much faster than you could on your own. It is that little jolt of, “oh, this changes things.”
I have had that feeling too. It is real.
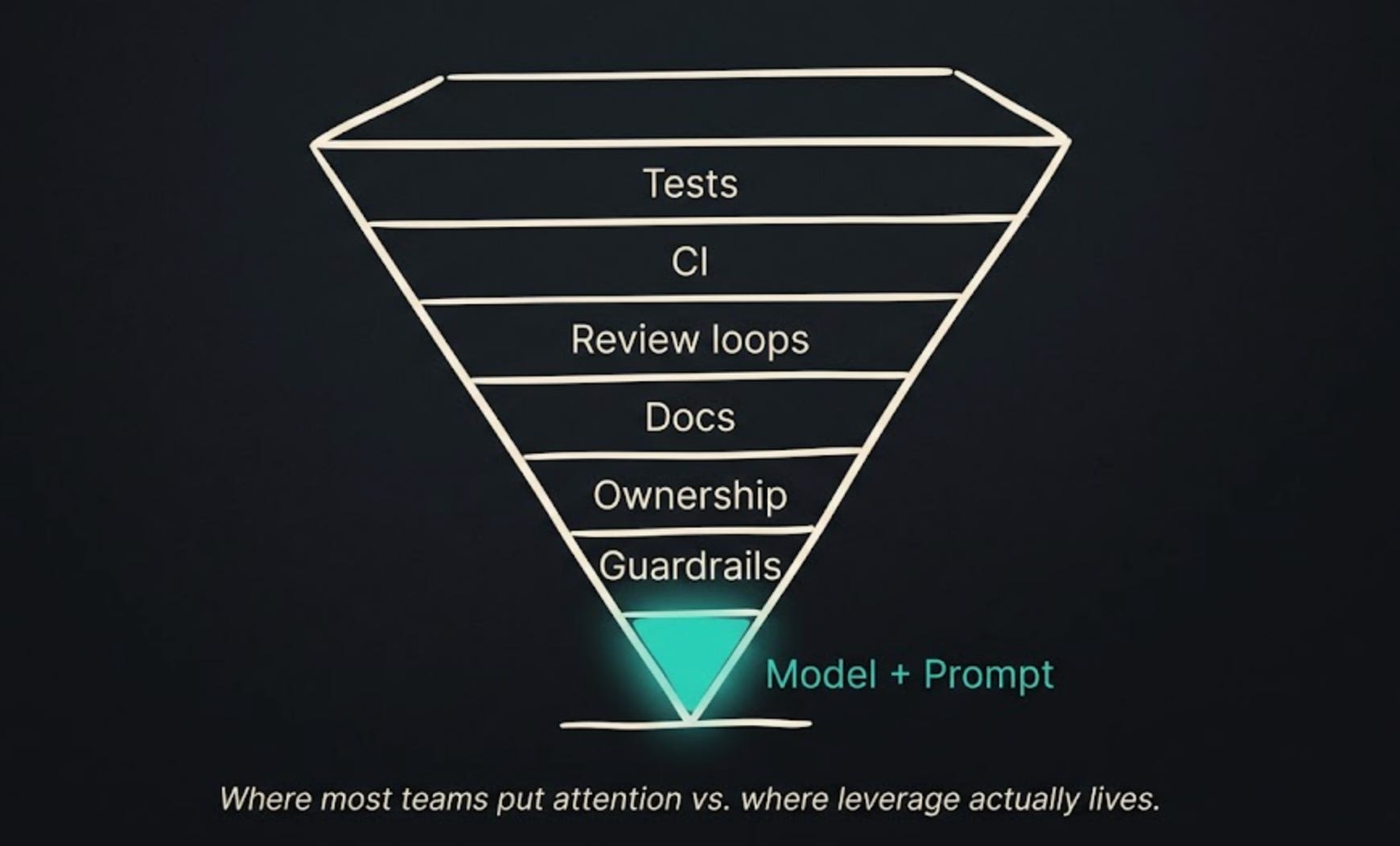
But a repeatable workflow needs more than a moment of leverage.
It needs a way to decide what work is appropriate for an agent. It needs enough context to produce useful output. It needs review loops. It needs standards. It needs guardrails. It needs test coverage. It needs clear ownership. It needs some way for the rest of the team to understand what happened without reading a novel in terminal scrollback.
That is where a lot of rollouts get stuck.
The first win makes everybody more ambitious. The operating model does not catch up fast enough.
Weak specs become more expensive, not less
One thing I have noticed in my own work is that agents raise the premium on clarity.
That sounds backward at first. These tools are supposed to make it easier to move fast, and they do. But they also punish vague thinking faster than older workflows did.
If a human engineer gets a fuzzy request, there is usually some natural friction in the process. Maybe they ask clarifying questions. Maybe they interpret charitably. Maybe they delay a little while they think through tradeoffs. The pace itself creates time for ambiguity to surface.
Agents often compress that loop.
You can hand an agent an undercooked spec and get something back almost immediately. Sometimes it even looks pretty good on first pass. That can create a dangerous illusion that the work was well-scoped when really the ambiguity just got converted into hidden defects, wrong assumptions, or shallow output faster.
That is one reason context quality matters so much more than people first expect. A lot of teams are still treating the prompt like the main input. In practice, the quality of the thinking and documentation behind the prompt matters much more than the cleverness of the wording itself.

A few of the teams I have talked to are basically using docs as the bridge between product thinking and AI execution. Not because they enjoy extra process, but because the workflow falls apart without some stable place to clarify intent.
Review eats the savings the agent created
This is another quiet failure mode.
The agent is fast. The human review loop is not.
If the output is simple, bounded, and easy to verify, that can still be a great trade. But once the work touches real product behavior, hidden assumptions, edge cases, or messy integration points, the review burden can expand quickly.
I have heard this from multiple teams in slightly different forms. They are not saying the tools are useless. They are saying the gains get fuzzier once you count the time spent checking whether the output is actually right.
Sometimes the code compiles but misses the point. Sometimes the tests pass but the workflow is wrong. Sometimes the feature works in the happy path and quietly breaks the thing next to it. Sometimes the agent made a reasonable local choice that does not fit the larger product or architectural intent.
That concern is not just anecdotal. MIT Sloan Management Review recently warned that layering AI-generated code onto already messy systems can create new maintenance burden and tangled dependencies that slow future development rather than simplifying it.
None of that is new, exactly. Human teams have always dealt with versions of this. But agent speed changes the economics. If the system can generate follow-on work faster than the team can review it, the bottleneck just moves upstream and piles up there.
That is usually the moment when teams realize the foundation work matters more than the demo did.
The social layer is more fragile than people admit
Some of the hardest rollout problems have very little to do with code generation itself.
They have to do with trust.
When one person on the team becomes very effective with AI tools, that can create a strange dynamic. The gains are real, but the workflow can become personal. It lives in their prompts, their habits, their documents, their preferred harness, their review style. Other people can see the results, but they cannot always see the method clearly enough to adopt it themselves.
That creates a local superpower without a shared operating model.
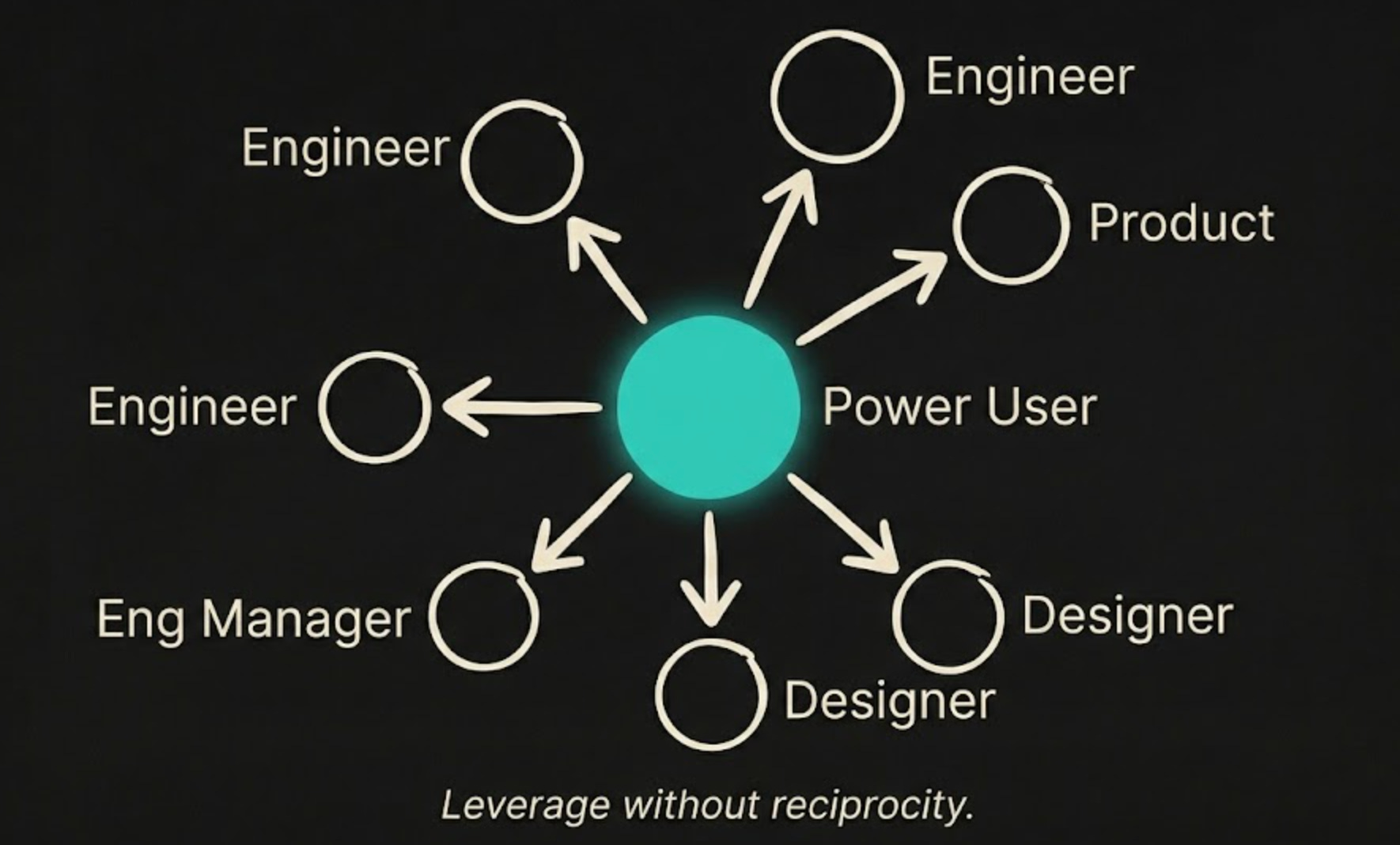
I think that is one reason so many rollouts stall in the gap between one power user flying and the team actually changing how it works.
If product cannot follow the flow, handoffs get brittle. If engineering leadership cannot evaluate quality, trust gets thin. If other developers cannot reproduce the process, adoption stays uneven. If everything depends on one interpreter sitting closest to the harness, then the company has not really become more AI-native. It has just created a new bottleneck.
Most teams I talk to do not yet have a clear answer for what the agent is and is not allowed to touch.
For teams I have talked to, this often shows up as a coordination problem before it shows up as a capability problem.
The tool can do something impressive.
The team does not yet know how to absorb it.
Teams want leverage without chaos
One thing I have not heard much in customer discovery is a loud demand for maximum autonomy right out of the gate.
What I hear more often is something simpler.
Teams want leverage without chaos. They want faster iteration without mystery. They want help with implementation, debugging, documentation, test writing, and codebase exploration, but they still want to know where judgment lives. They want to move quicker without feeling like the whole system got harder to trust.
That is a very different need from the self-driving software team framing.
It is less cinematic. It is also much more believable.
The teams I see making progress here are usually not the ones chasing the most aggressive model claims. They are the ones redesigning how work flows around the model.
If you are trying to make one of these rollouts stick, the practical work is not glamorous. Tighten the specs. Improve the docs. Strengthen the tests. Put better review loops in place. Be explicit about ownership. Set clearer boundaries around what the agent is allowed to do.
That is what makes the gains durable.
And next week I want to get more specific about what is actually working, based on conversations with teams that have pushed a little further past the stall.